
In the vast ocean of NLP tools, some hidden gems remain uncharted. While NLTK and spaCy dominate the landscape, a constellation of lesser-known libraries awaits discovery.
These underappreciated resources offer unique capabilities that could revolutionize your natural language processing projects. From intent parsing to memory-efficient topic modeling, these five libraries might be the secret ingredients your NLP toolkit needs.
Curious about the untapped potential lurking in the shadows of the giants? A world of innovative features and unexpected enhancements beckons.
Snips NLU
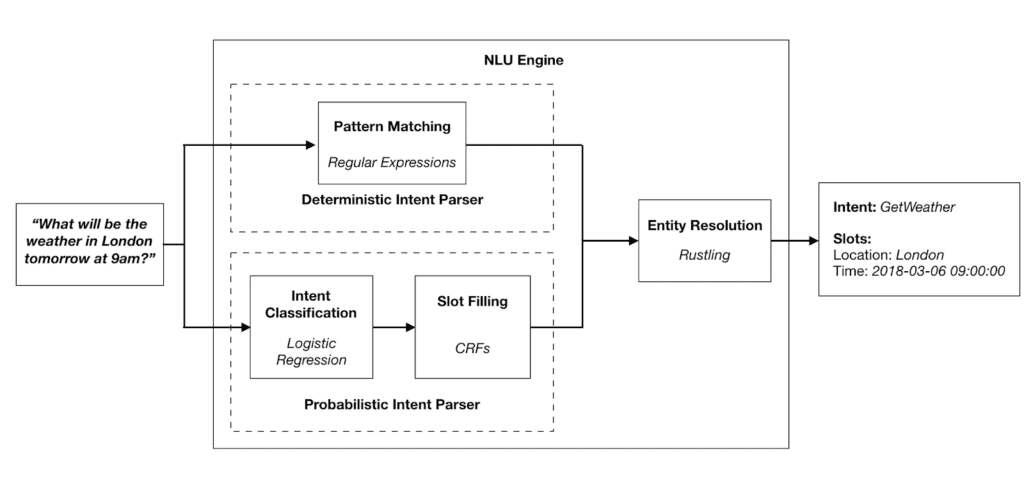
At the forefront of open-source natural language understanding libraries, Snips NLU offers a robust solution for developers seeking to implement intent parsing and entity extraction in their applications.
You’ll appreciate its language-agnostic design and offline capabilities, ensuring data privacy.
Snips NLU’s deterministic engine allows for fine-tuned control, while its machine learning components adapt to your specific use cases.
It’s a powerful tool for building voice-controlled interfaces without compromising user freedom.
Happy Transformer
While Snips NLU excels in intent parsing and entity extraction, Happy Transformer pivots to a broader range of NLP tasks, providing a user-friendly interface for utilizing pre-trained transformer models like BERT, RoBERTa, and XLNet. You’ll find it simplifies complex NLP operations, offering:
| Task | Models Supported | Key Attribute |
|---|---|---|
| Text Classification | BERT, RoBERTa | Multi-label |
| Question Answering | BERT, DistilBERT | Context-aware |
| Next Sentence Prediction | BERT, XLNet | Bi-directional |
| Text Generation | GPT-2, XLNet | Fine-tuning |
TextAugmentation-GPT2
TextAugmentation-GPT2 stands out as a powerful tool for generating synthetic training data, leveraging the capabilities of OpenAI’s GPT-2 model to augment existing datasets with contextually relevant examples.
You’ll find it invaluable for expanding limited datasets, enhancing model robustness, and investigating diverse linguistic variations.
It’s particularly useful when you’re working with scarce data or need to test your models against a wider range of inputs.
Spark NLP
Leveraging the power of Apache Spark, Spark NLP offers a scalable, production-ready natural language processing library that seamlessly integrates with existing big data ecosystems. You’ll find it invaluable for processing extensive text datasets efficiently.
It supports multiple languages and provides pre-trained models for various NLP tasks. Spark NLP’s distributed computing capabilities allow you to break free from single-machine constraints, enabling rapid analysis of immense corpora without compromising accuracy.
Gensim
Designed for topic modeling and document similarity retrieval, Gensim stands out as a robust, memory-efficient library that’s particularly adept at processing large text corpora.
You’ll find it excels in implementing algorithms like Latent Dirichlet Allocation and Word2Vec.
Gensim’s streaming corpus capability allows you to work with datasets larger than RAM, offering unparalleled freedom in handling massive text collections without hardware constraints.